Table of Contents
Preamble
We’re building a new company from the ground up and I’ve decided to go the software way in regards of storage. We’ve used to be using LSI MegaRAID but the experience was less than stellar. Performance is fine, but random driver failures caused a fair amount of trouble during the years. I also have to mention that LSI Support is one of the worst I’ve ever had to deal with.
So I figured, I might as well give software RAID a go, it can’t be worse than this. Since most of our infrastructure is Windows-based I picked Storage Spaces. I intend this post as a guide for those who are in the same boots as I am, maybe it’ll save you a few days of work. Let’s start and do some benchmarks!
Basics
The problem with storage is that there are just so many variables. In means of Storage Spaces, you can decide on, at least:
- Number of HDDs
- Number of SSDs
- RAID level
- Interleave size
- Number of columns
- Provisioning type
- Filesystem
- Cluster size
- Tiering
- Write-back Cache
- Rebuild options
HDD
Pretty obvious, this defines how much space you’ll get at the end. More disks mean more IOPS and more space. On the other hand, a bigger number of low capacity disks take more rack space.
SSD
If you’re dealing with a pure SSD array, the setup is obvious, but usually, the purpose of SSDs is to speed up the HDDs. The configuration you apply here can get pretty crucial as you’ll see in the tests.
You could just put the SSDs into the arrays without any tailoring, but simply hoping that important data will take its place there doesn’t make much sense.
If you use parity, you most definitely want to use the SSDs as Write-back Cache (see below).
If you want mirroring, WBC isn’t really useful because the array, and more importantly, writes are pretty damn fast on their own, but you can set up a tiered storage (again, see below). Conceptually, tiered storage does make sense with parity too, but it’s not implemented in Storage Spaces.
So to sum it up, if you use mirroring, go for tiering, if you use parity, go for WBC.
RAID Level
This is also a fundamental choice to make. With SS you can have Simple (RAID0), Two-way mirror (RAID10), Three-way mirror (you tell me what RAID level this is), Single parity (RAID5) or Dual parity (RAID6) layouts. I’m yet to find a sensible use case for RAID0 and Two-way mirror, so I’ll just skip them altogether.
Microsoft and others only recommend parity layouts for archiving purposes and I can only support this sentiment – you’ll see way. RAID10 is pretty damn good, but of course, it’s the most expensive one.
Interleave size
TL;DR this is stripe size in Microsoft language. The default is 256kB which is pretty much in the middle. I’ve found that it provides a good balance overall so I don’t recommend changing it.
Number of columns
This may be a bit difficult to get a grip on. A nice TechNet article definition:
The number of columns specifies how many physical disk data is striped across.
So basically, this number defines how many disks are accessed at the same time, which greatly affects performance. The more disks providing I/O, the faster the data transfer. OTOH if it’s too big, it may cause latency.
Additionally, the number of columns also defines how many disks you’ll need to extend the virtual disk later. For example, if you have 12 disks in RAID10 and column count is 6, that means data is striped across 6 disks and their mirrors, i.e. all disks in the array. So when you want to expand, you can only add 12 additional disks at a time – this may not always be feasible, especially when we’re talking about 8TB disks.
Provisioning
You can have fixed or thin provisioning. Fixed is pretty obvious, and thin provisioning means you can allocate more disk space to a certain application than what’s actually, physically available. This is more interesting when you’re deploying VMs where usage is often unpredictable.
Filesystem
We have a new kid on the block called ReFS which promises a lot of things. I’ve performed some tests and it was like half as fast as NTFS so I believe your only sane choice still remains NTFS.
Cluster size
This is the size of an allocation unit on the file system. For example, if you have a cluster size of 64kB, every file will take up at least this much space on the disk, even if it’s smaller. Thus if you have A LOT of files smaller than the cluster size, you’ll waste some disk space. OTOH if cluster size is too small, your volume size will be limited because there’s also a limit on the number of clusters.
Since we’re talking about big volumes, I really recommend picking the biggest allowed size of 64kB, which is, by the way, also the only currently available option for ReFS.
Tiering
Storage Spaces has this nifty feature called tiered storage where frequently accessed data is automatically moved to the SSD parts of an array. It may come handy in certain setups.
Write-back Cache
This is Microsoft’s answer to cheap RAM and BBUs on the HW controllers. Instead of relying on volatile memory and a battery, they simply use SSD for caching so that you don’t need to worry about a sudden power-off because the data will still be there after the reboot. Neat, isn’t it? With parity, this is most definitely a must-have.
Rebuild
The trivial procedure is when you notice a disk failure, you replace the disk, start the rebuild and once finished, remove the failed disk from the pool.
You can also have a hot spare so that rebuild starts as soon as the failure’s noticed by SS, but of course this is also a waste of rack space.
Finally, since Windows Server 2012 R2, you can also leave some unused space in the storage pool and that way the rebuilding will use that unused space that’s spread across all disks in the array. This is claimed to speed up the process by a lot – from my experience, not quite. A 8TB traditional rebuild took about 13 hours, and with this method, after 2 hours it completed only about 20%. Not to mention this setup also needs you to reduce column count that in turn hurts performance. So my recommendation is to just stick to manual rebuild and don’t waste your disk space.
Benchmarks
Let’s get down to business and see how this beast performs. Test setup:
- Intel R1208WTTGS
- Intel Xeon E5-2630 v3
- 32 GB Kingston DDR4 LRDIMM 2133 MHz Q4 RAM
- Intel JBOD2000 (unfortunately this is only SAS2, but it should be sufficient for HDDs)
- LSI 9300-8e HBA
- HGST Ultrastar He8 (SAS 12Gb/s, 7200 RPM, 128MB)
- Samsung 850 Pro
- Windows Server 2012 R2 + all OS and driver updates
The tests were performed with ATTO Disk Benchmark 3.05:
- Transfer Size: 4kB to 64MB
- Total Length: 8GB
- Direct I/O (Overlapped I/O)
- Queue Depth: 4
RAID10
First I wanted to see RAID10 performance. I’ve created three virtual disks with the following numbers:
- 12 HDD, 0 SSD, No tiering, No WBC, Column count: 6
- 12 HDD, 2 SSD, Tiered, 1GB WBC, Column count: 1
- 12 HDD, 4 SSD, Tiered, 1GB WBC, Column count: 2
WBC and column settings are default values.
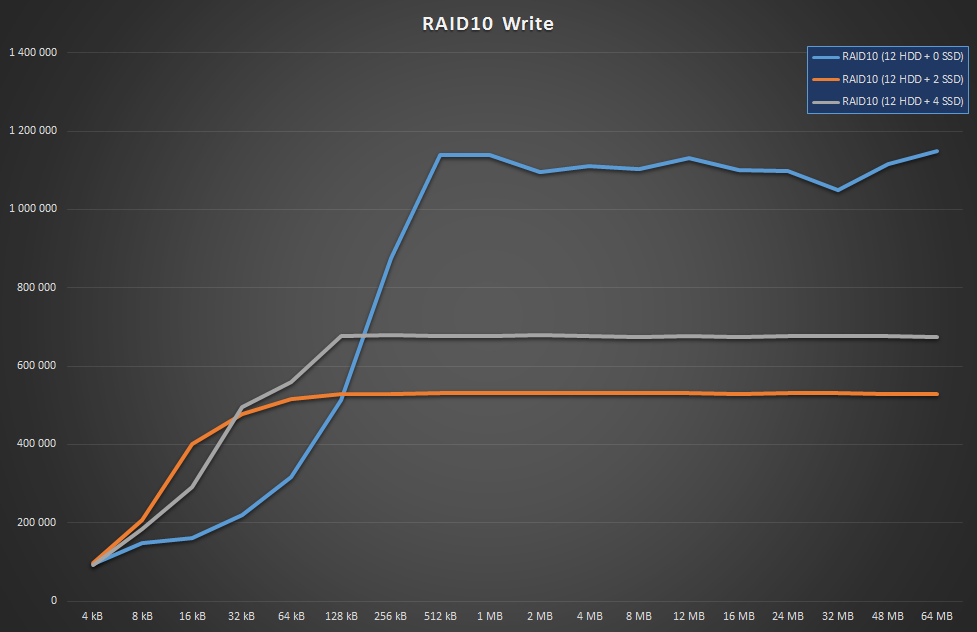
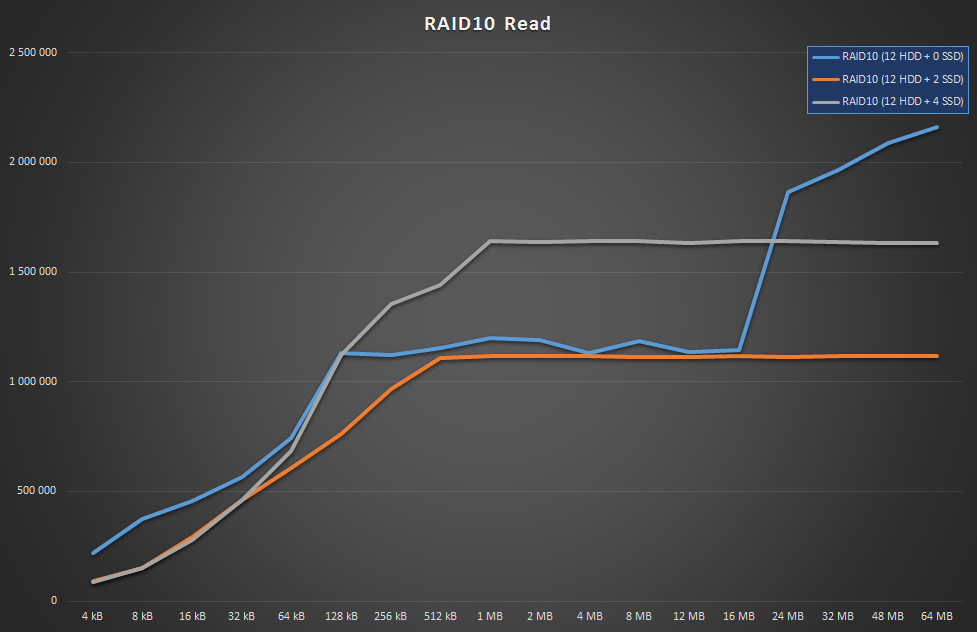
Wait, what? The array is actually faster without SSDs? That’s right, and it’s because the small number of SSDs limits column count, and there’s only so much performance those 2 or 4 SSDs can provide. Of course benchmarking a tiered storage this way won’t really show the actual advantage of tiering since the SSDs would surely help with lots of concurrent, random I/O. OTOH for that, you’d probably want to get a pure SSD array anyway. The point is, for regular static loads, such as file shares, you won’t get much performance penalty if you avoid SSDs altogether, SS does its job pretty well.
RAID5
Like I said, parity spaces don’t support tiering so none of the virtual disk setups had it.
- 12 HDD, 0 SSD, 32MB WBC, Column count: 8
- 12 HDD, 2 SSD, 1GB WBC, Column count: 8
- 12 HDD, 3 SSD, 1GB WBC, Column count: 8
- 12 HDD, 4 SSD, 1GB WBC, Column count: 8
Again, WBC and column settings are defaults. Apparently SS allocates some WBC even if there’s no SSD at all. When using parity spaces with WBC, you want to set the SSDs’ usage to Journal so that it will be dedicated to caching:
Set-PhysicalDisk –Usage Journal –FriendlyName PhysicalDisk14From what I understand, the number of SSDs you should use greatly depends on the parity in question:
- RAID5: use multiples of 2 (one for data, one for parity)
- RAID6, use multiples of 3 (one for data, 2 for parities).
In fact, SS won’t even allocate the 1GB WBC if you use less than this. Well, unless you tell it to do so via the command line, to be exact. Now let’s see how this thing performs:
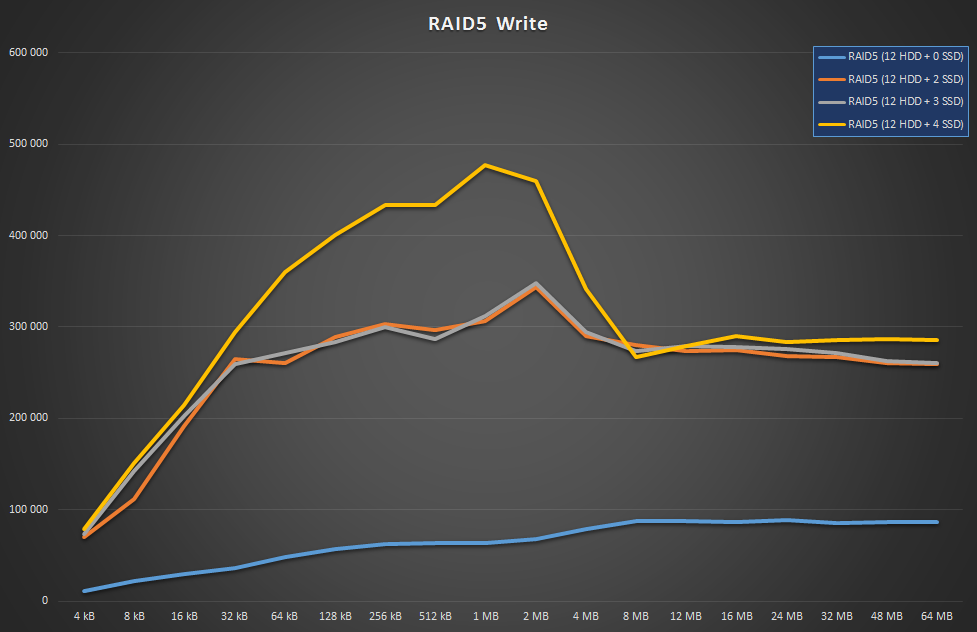
As you can see, parity writes are absolutely miserable without WBC. And to back my comment above, it’s obvious that adding a single SSD to 2 SSDs has no effect at all, you’ll need pairs of SSDs to get any benefit.
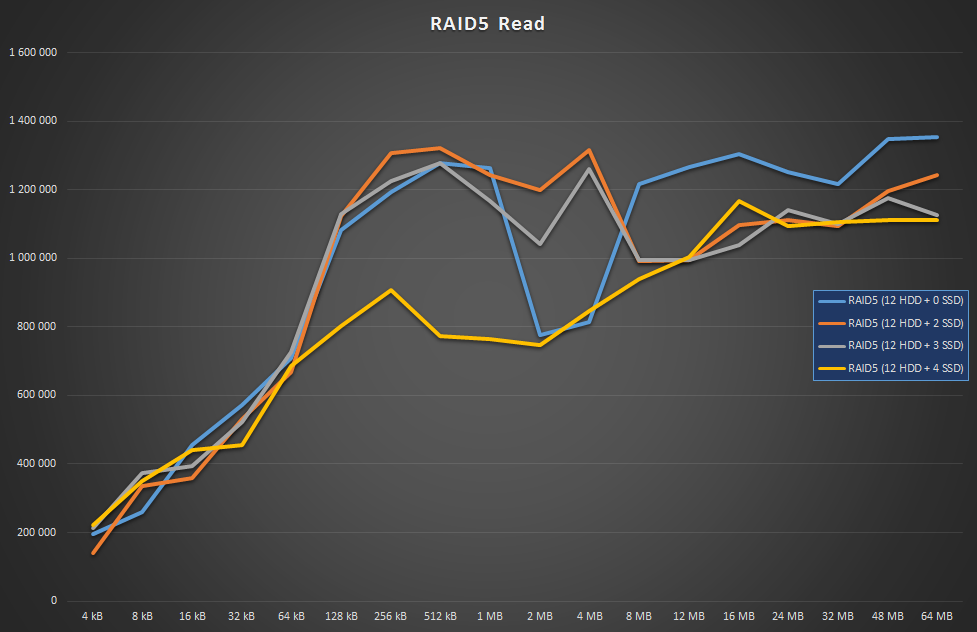
I’m not quite sure why read with 4 SSDs took a hit around the middle range, but nevertheless, they all performed pretty well.
RAID6
Again, no tiering and default WBC/count settings:
- 12 HDD, 0 SSD, 32MB WBC, Column count: 12
- 12 HDD, 3 SSD, 1GB WBC, Column count: 12
- 12 HDD, 4 SSD, 1GB WBC, Column count: 12
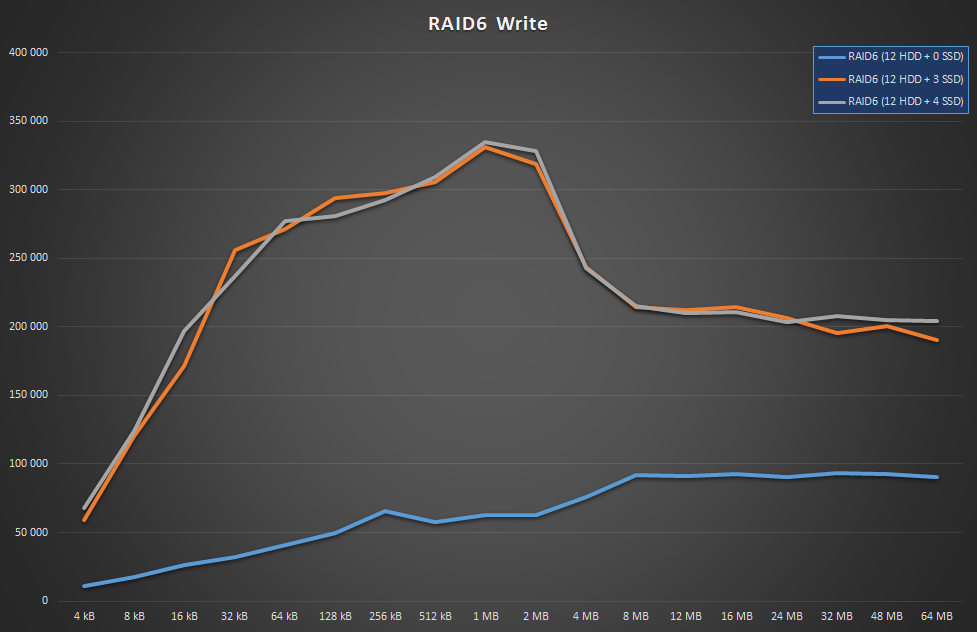
Again, no change with the extra SSD and horrible numbers without WBC. It’s pretty similar to RAID5, except even slower. In this case, I assume I’d have to have 6 SSDs to improve throughput, but IMO that’d be rather excessive for an array with 12 HDDs (1:2 ratio).
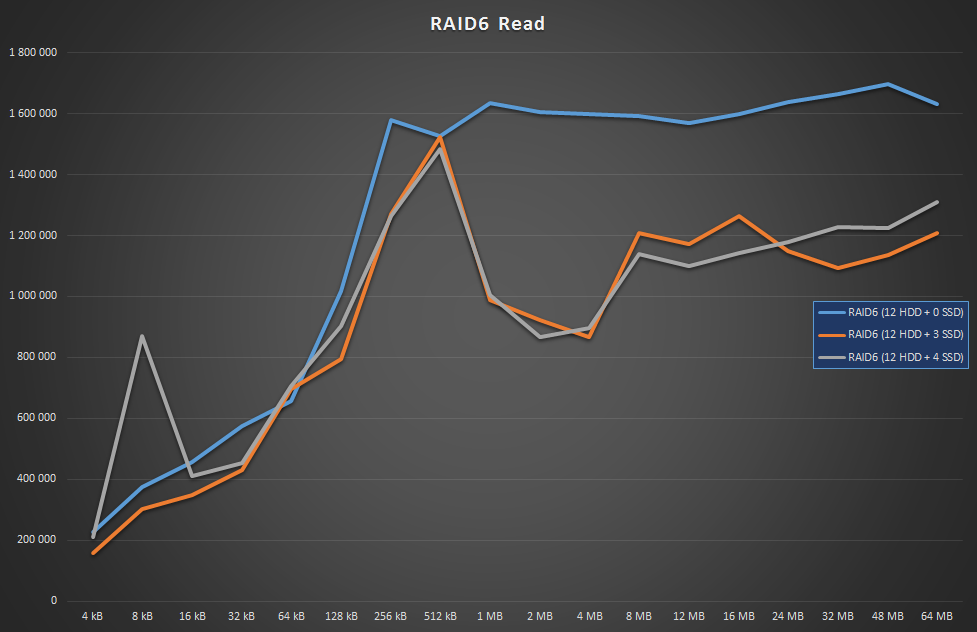
This time the WBC-applied arrays’ performance degraded during the greater chunks. Why a write cache kills reads is beyond me, hopefully someone will come up with an answer in the comments. OTOH 1GB/s is still pretty decent anyway.
RAID Levels Compared
Now let’s pick the best from RAID10, RAID5 and RAID6 and see how they stand against each other.
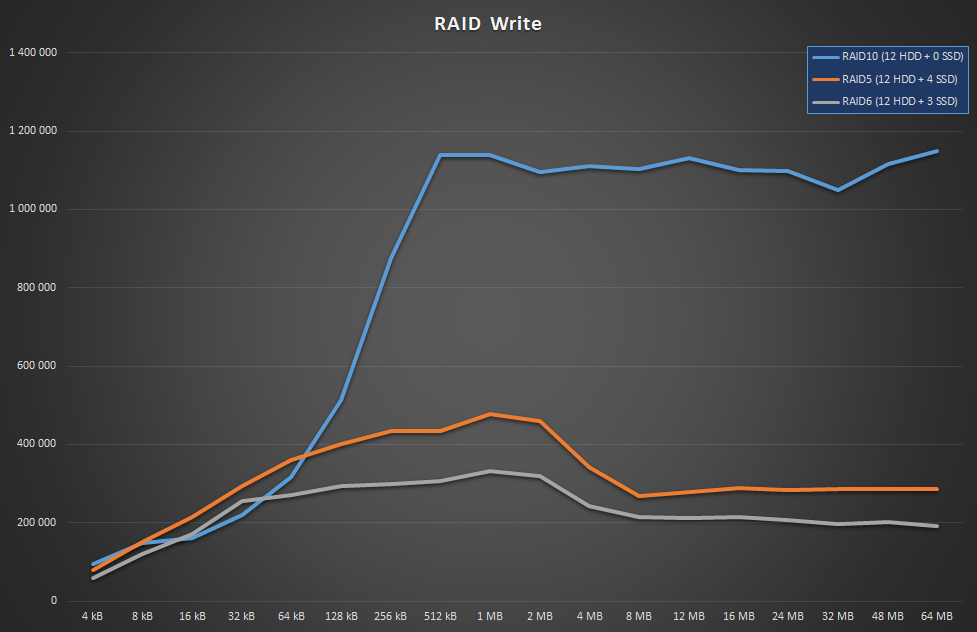
Yeah, nothing to see here, move along. As mentioned earlier, you do want to use RAID10 if your load is write-intense. Even with 3 or 4 SSDs added to the mix, parity layouts struggle heavily.
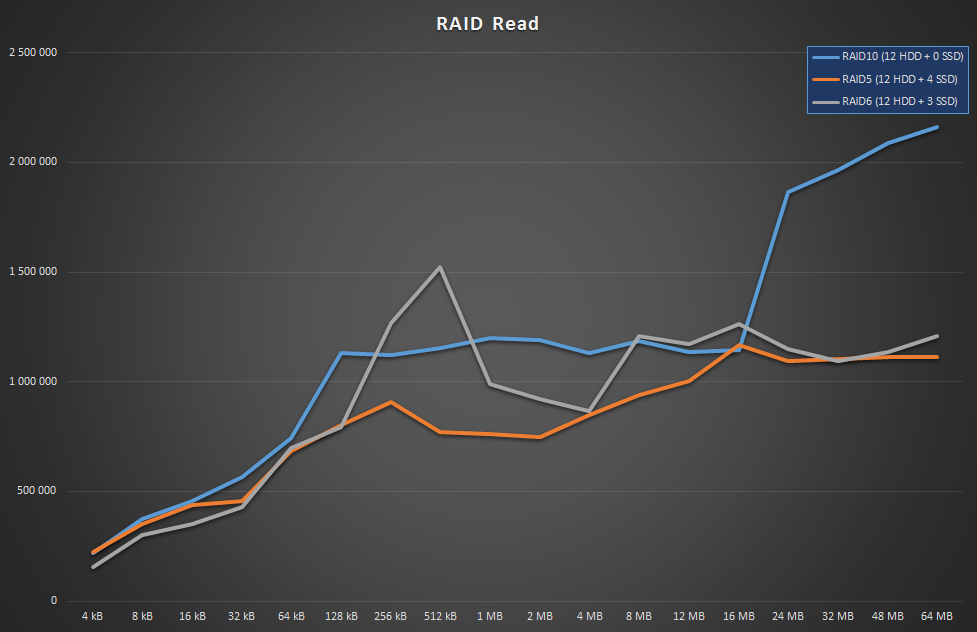
OTOH reads are doing fine, so if those dominate your load, just go with parity and enjoy your enormous free space.
SSD Capacity
I was wondering if SSD capacity had any impact on parity performance, because 2 of my SSDs were 512GB ones and the remaining 2 were 1TB versions. Yes, the cache is only 1GB by default, and there’s even a hard limit of 100GB if you set it up manually (tho it’s really discouraged), but still, you can never know. So I just had to test it:
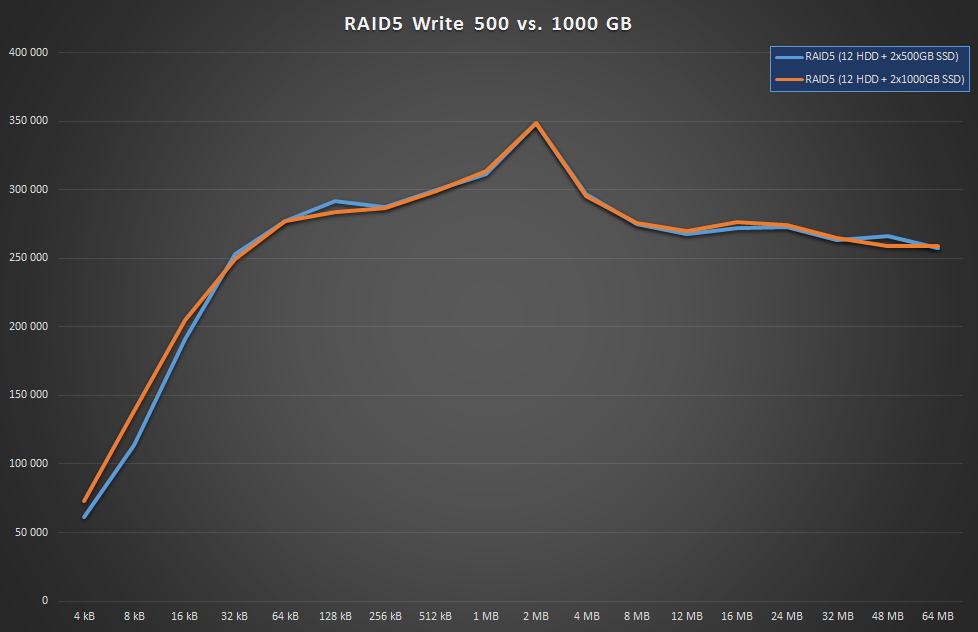
The answer is nope, not in the slightest.
Storage Spaces 2016
I was also really curious if the Windows Server team managed to achieve any improvement with parity spaces in the latest preview (Technical Preview 3 at the time of writing). It’s really strange and one has to wonder, what’s the cause of this write bottleneck?
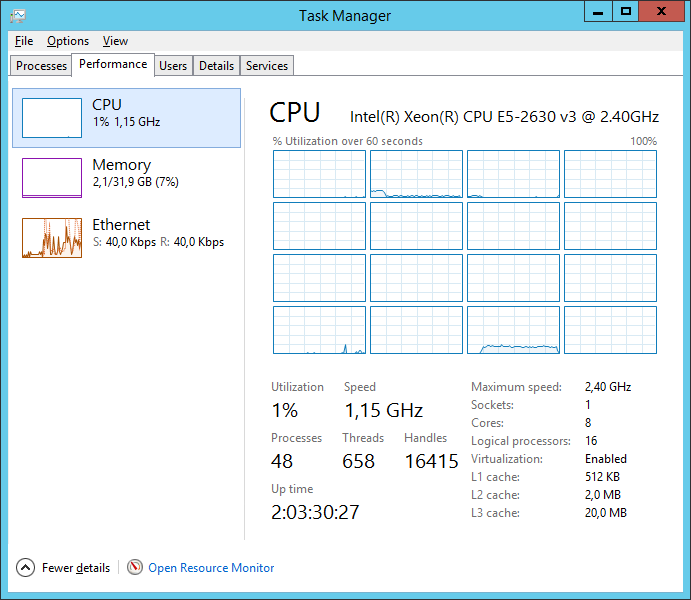
It’s certainly not the CPU or memory so the only other thing I can think of is that their implementation is simply bad, err, suboptimal. Anyway, check out Windows Server 2016:
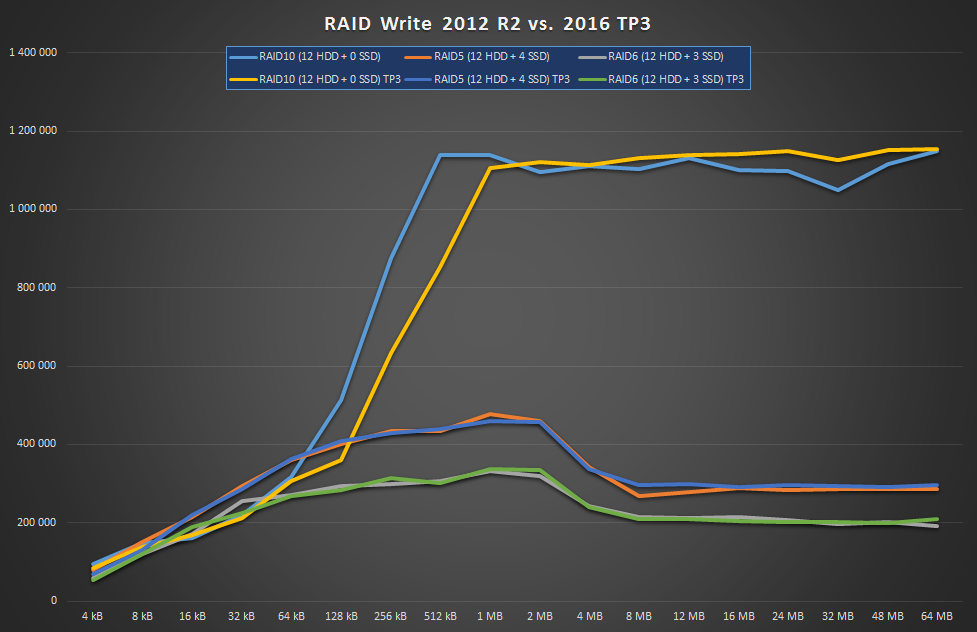
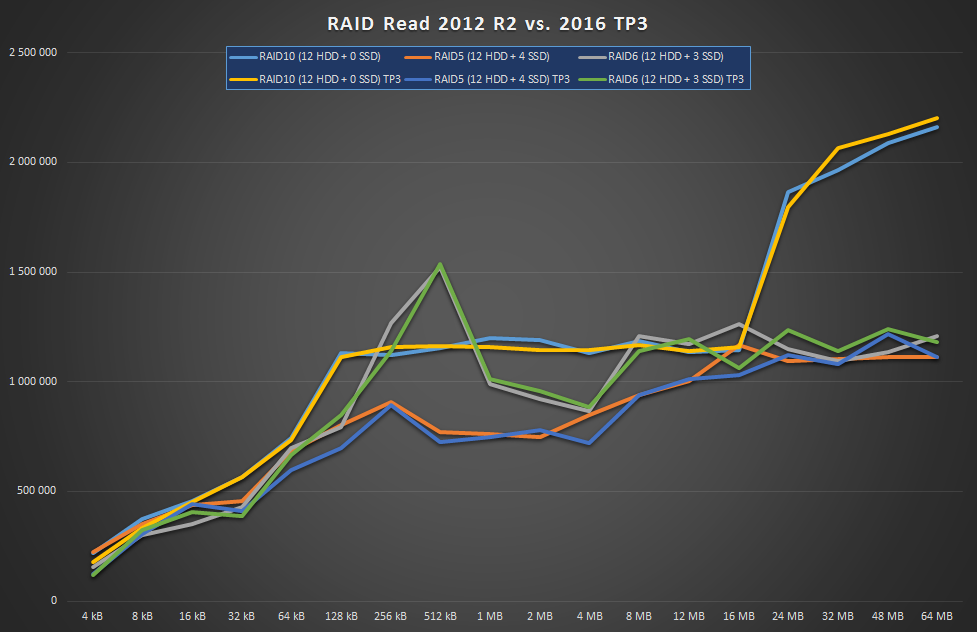
As you can see, there’s absolutely zero improvement. Shame on you! Anyway, I’ve noticed one new feature they’ve added to the GUI:
Nice addition, keep ‘em coming!
Conclusion
After these test performed, I decided to have 2 kinds of storage in the company:
- 12 HDDs in RAID10 without SSDs: for static storage (i.e. network shares)
- 12 HDDs in RAID5 with 4 SSDs: for backup
I’ll also need a pure SSD array for VMs and other heavy I/O, but the SSD enclosure is yet to be tested, so stay tuned for part 2!